 Scrapy实战之豆瓣top250电影信息的爬取
Scrapy实战之豆瓣top250电影信息的爬取
# 简单使用
# 1.基操(简单的项目命令)!
# (1)创建项目:
(小知识点:<>为必填项;[]为选填项!小技巧1:pycharm终端输入scrapy可以查看一些帮助,有助于我们写那些难记的命令!小技巧2:scrapy+命令关键字,可以查看有关于此命令的详细用法!)
1.首先: cd+要放scrapy项目的文件夹路径
2.第二步: 通过scrapy命令可以很方便的新建scrapy项目。
语法格式:scrapy startproject <project_name> [project_dir]
该命令会在project_dir文件加下创建一个名为project_name的Scrapy新项目。如果project_dir没有指定,project_dir与project_name相同。执行命令:scrapy startproject baidu之后会在指定文件夹创建如下文件:
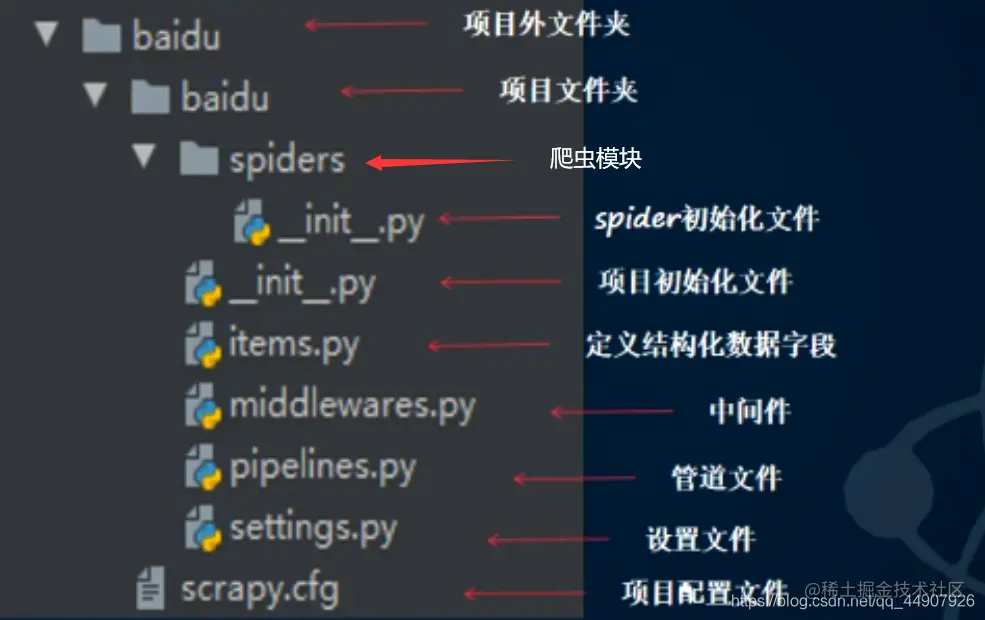
# (2)创建爬虫文件
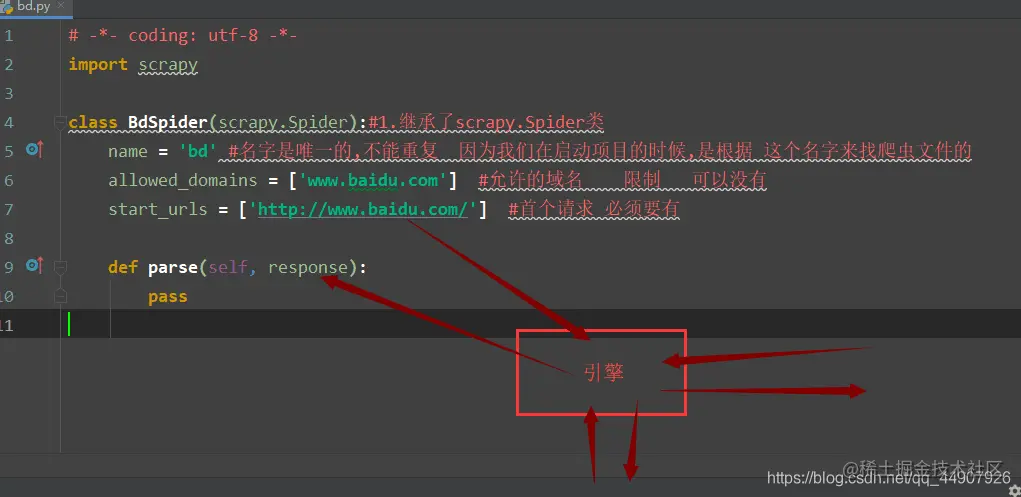
{创建一个bdSpider的类,它必须继承scrapy.Spider类,需要定义以下三个属性:name: spider的名字,必须且唯一start_urls: 初始的url列表parse(self, response) 方法:每个初始url完成之后被调用。这个函数要完成一下两个功能:解析响应,封装成item对象并返回这个对象提取新的需要下载的url,创建新的request,并返回它
我们也可以通过命令创建爬虫
语法格式:scrapy genspider [-t template] 运行命令:scrapy genspider bd www.baidu.com会在spiders文件下生成bd.py文件}**1.首先: (opens new window)** cd 到项目下2.第二步: scrapy genspider [options] scrapy genspider bd www.baidu.com会创建在项目/spider下 (opens new window) ;其中bd 是爬虫文件名, www.baidu.com (opens new window) 是 url(域名)执行命令:scrapy genspider bd www.baidu.com之后再项目/spider下创建的文… (opens new window)
# -*- coding: utf-8 -*-
import scrapy
class BdSpider(scrapy.Spider): #继承了scrapy.Spider类
name = 'bd' #名字是唯一的(不重复) 因为我们在启动项目的时候,是根据这个名字来找爬虫文件的
allowed_domains = ['www.baidu.com'] #允许的域名 (限制) 可以没有这个限制!
start_urls = ['http://www.baidu.com/'] #首个请求(必须要有) 不然开始都开始不了,怎么让整个框架运行下去呢!
def parse(self, response): #必须是parse函数 不可以乱改名 接收下载器下载的数据
print("*******") #用于更直观的观察框架能否正常运行!
print("*******")
print("*******")
print("*******")
print("*******")
print("*******")
print(response) #response对象
#获取数据 两种方法:
print(response.body.decode()) #获取到的是字节码形式
# print(response.text)
复制代码
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
注意:最后引擎给spider模块的数据就给到了函数parse里的形参response:
# (3)运行爬虫文件
一步即可: scrapy crawl [options] 其中spider是爬虫文件名
执行命令:scrapy crawl bd
# 但是!我们运行爬虫文件之后,发现用于测试的print函数没有显示,经过检查终端输出的数据可知Scrapy框架是默认遵循robots协议的,所以咱们肯定获取不到数据了!!!
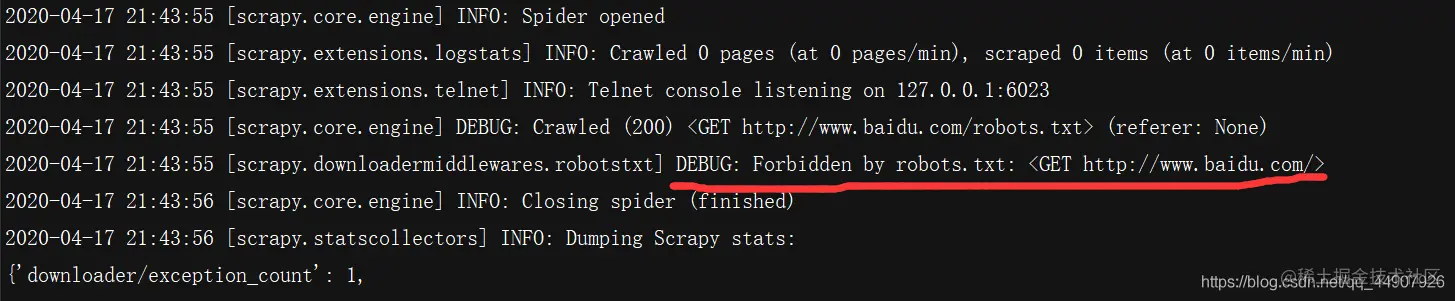
# 如何解决这个问题呢?
打开设置文件settings.py,将其中的以下代码更改为False即可!
# Obey robots.txt rules
ROBOTSTXT_OBEY = True
复制代码
2
3
拓展:第二种运行scrapy的方法!
cd 到爬虫模块spiders文件夹下,运行命令:
scrapy runspider 爬虫py文件名
注意:爬虫py文件名要带.py后缀!
复制代码
2
3
4
高级拓展:(注意:以上两种运行scrapy框架的方法都无法进行debug,非常不方便!万一出问题了,岂不是很难找!!!所以:推出第三种启动scrapy框架的方法-----django在创建项目的时候自动生成一个启动项目的py文件【manage.py或者main.py】,而scrapy框架没有,但是我们可以自己定义呀!!!!!)
1.在项目文件夹下创建名为main.py或者manage.py的py文件:
复制代码
2
2.在此py文件下编写代码如下:
from scrapy.cmdline import execute
import sys
import os
# 保证终端执行 "scrapy", "crawl", "bd" 这个命令运行不出现路径问题!(可以不写!)
sys.path.append(os.path.dirname(os.path.abspath(__file__)))
execute(["scrapy", "crawl", "bd"])
复制代码
3.现在,我们可以直接运行这个py文件,会发现会和前两种方法一样运行scrapy框架;而且,强大的是:我们还可以通过debug此py文件达到调试此scrapy框架的作用!!!
复制代码
2
3
4
5
6
7
8
9
10
11
12
# (2)实操(豆瓣电影top250首页电影信息的获取!)
# 1.创建项目:
scrapy startproject douban
# 2.创建爬虫文件:
scrapy genspider db www.summer.com (opens new window) (注意:这个域名是可以随便写的【但是必须要写哦!】,等爬虫文件生成之后再进相应的爬虫文件改为我们所需的即可!)
# -*- coding: utf-8 -*-
import scrapy
class DbSpider(scrapy.Spider):
name = 'db'
allowed_domains = ['movie.douban.com']
start_urls = ['https://movie.douban.com/top250']
def parse(self, response):
print("*********")
print("*********")
print("*********")
print("*********")
print("*********")
print(response.text)
复制代码
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
# 3.运行爬虫文件:
scrapy crawl db但是,我们运行之后发现又没有获取到数据哎!

造成这样的原因是:回想爬虫的基础,我们如果直接这样向网页发送请求进行爬取,那服务端一眼就看到咱是scrapy了,它还会理咱嘛?所以我们要设置请求头!
# 4.设置请求头:
在配置文件settings.py中找到如下代码取消注释并加入爬取网页请求头的User-Agent即可!

# 5.获取到电影名字:
{到现在,我们运行爬虫文件,Scrapy框架已经可以获取到网页的首页数据。那么,我们如何筛选出我们想要的电影的名字呢?考虑到我们如果利用xpath匹配,可能要多次尝试才能正确匹配到,那就需要我们一次又一次的运行咱的项目,多麻烦啊!咱都这样想了,人家大牛也这样想啊,所以,在这里有个贼帅贼帅的牛皮的方法:使用shell交互式平台:(注意1:它是遵循settings设置的;注意2:一定要到咱的项目文件夹下运行;) 首先:cd到我们项目的文件路径下。然后:输入命令scrapy shell url (start_url) 即可!这样:它其实就请求到了此url的数据(跟上面运行爬虫文件得到的数据一模一样)!!!}
首先:打开我们的shell交互式平台。 再此项目中:输入命令scrapy shell movie.douban.com/top250 (opens new window)
第二步:在shell交互式平台中匹配我们所需的电影数据。 输入:response.xpath('//div[@class="info"]/div/a/span[1]/text()')
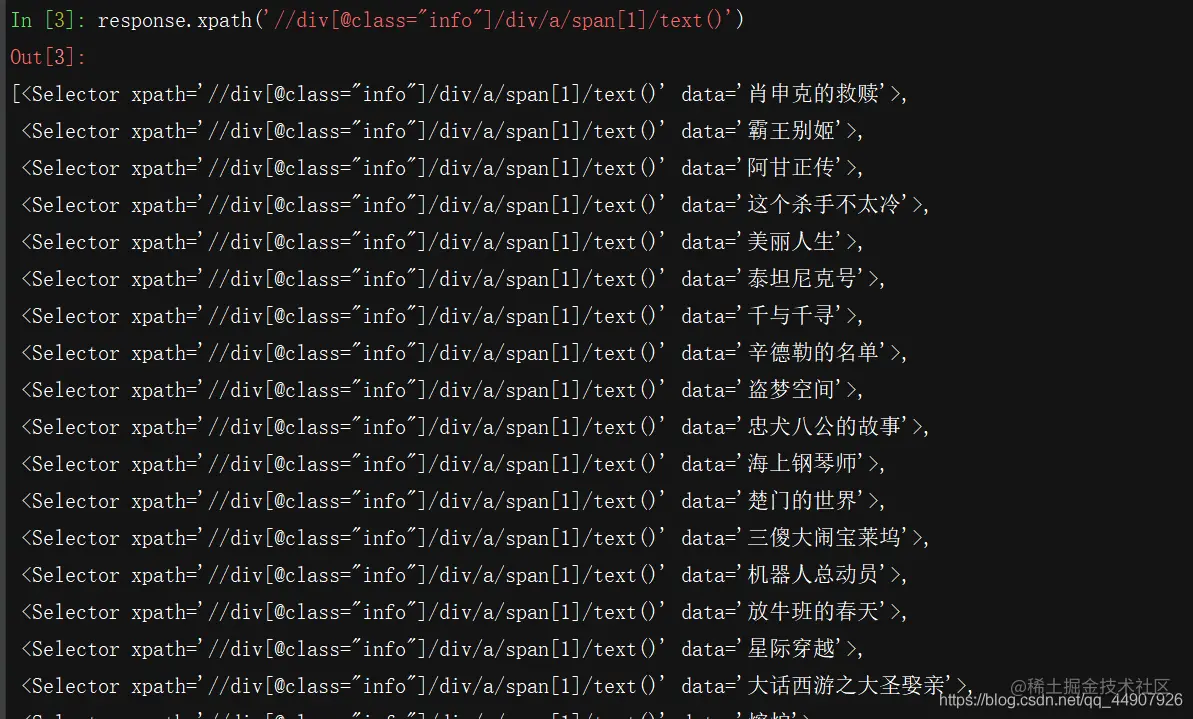
(会发现:这得到的是一个selector对象!而我们得到的数据就是用的response对象自带的xpath匹配到的(生成了response之后就会自动生成selector对象)!与我们正常用的xpath不同,它获取到的数据在selector对象里,如上图:)
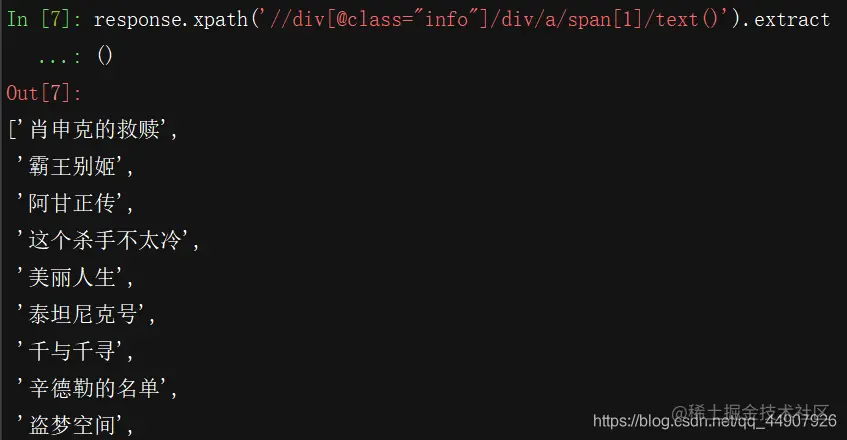
第三步:从selector对象中提取电影名字使用selector对象的方法.extract()。这个方法可以提取到selector对象中data对应的数据。response.xpath('//div[@class="info"]/div/a/span[1]/text()').extract()
# 6.将获取到的电影的信息存储到text文本中
{注意:如果想要存储数据,就要用到管道。这就涉及到了items.py文件(定义结构化数据字段)和pipelines.py文件(管道文件)。}
首先:操作items.py文件因为我们只需要存储一个信息,所以定义一个字段名即可!{定义公共输出数据格式,Scrapy提供了Item类。Item对象是用于收集剪贴数据的简单容器。它们提供了一个类似词典的API,提供了一种方便的语法来声明它们的可用字段。 scray.Item对象是用于收集抓取数据的简单容器,使用方法和python的字典类似。编辑项目目录下items.py文件。
然后我们只需要在爬虫中导入我们定义的Item类,实例化后用它进行数据结构化。}
# -*- coding: utf-8 -*-
# Define here the models for your scraped items
#
# See documentation in:
# https://docs.scrapy.org/en/latest/topics/items.html
import scrapy
class DoubanItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
#需要定义字段名 就像数据库那样,有字段名,才能插入数据(即存储数据)
# Field代表的是字符串类型!!!
films_name=scrapy.Field() #定义字段名
复制代码
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
第二步:在爬虫文件中操作数据,使其与管道建立桥梁{到目前为止,我们通过scrapy写出的爬虫还看不出优越性在哪里,并且上面的爬虫还有个很严重的问题,就是对文件的操作。每次调用parse方法会打开文件关闭文件,这极大的浪费了资源。parse函数在解析出我们需要的信息之后,可以将这些信息打包成一个字典对象或scray.Item对象(一般都是item对象),然后返回。这个对象会被发送到item管道,该管道会通过顺序执行几个组件处理它。每个item管道组件是一个实现简单方法的Python类。他们收到一个item并对其执行操作,同时决定该item是否应该继续通过管道或者被丢弃并且不再处理。item管道的典型用途是:
清理HTML数据验证已删除的数据(检查项目是否包含某些字段)检查重复项(并删除它们)将已爬取的item进行数据持久化}
# -*- coding: utf-8 -*-
import scrapy
from ..items import DoubanItem #因为我们要使用包含定义字段名的类,所以需要导入
class DbSpider(scrapy.Spider):
name = 'db'
allowed_domains = ['movie.douban.com']
start_urls = ['https://movie.douban.com/top250']
def parse(self, response):
# 获取电影信息数据
films1_name=response.xpath('//div[@class="info"]/div/a/span[1]/text()').extract()
# 交给管道存储
# 使用DoubanItem
item=DoubanItem() #创建对象
item["films_name"]=films1_name #值是个列表,因为xpath匹配到的数据都扔到列表里了!
# item可以理解为一个安全的字典 用法与字典相同
print("item里面是:",dict(item)) #可以转换为字典
return item #交给引擎 引擎要交给管道,需要打开管道
复制代码
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
第三步:我们要将数据提交给管道,所以需要打开管道要激活这个管道组件,必须将其添加到ITEM_PIPELINES设置中,在settings.py文件中:
(在此设置中为类分配的整数值决定了它们运行的顺序:按照从较低值到较高值的顺序进行。注意:这个管道的目的只是介绍如何编写项目管道,如果要将所有爬取的item存储到json文件中,则应使用Feed导出,在运行爬虫是加上如下参数:scrapy crawl bd -o films.json)
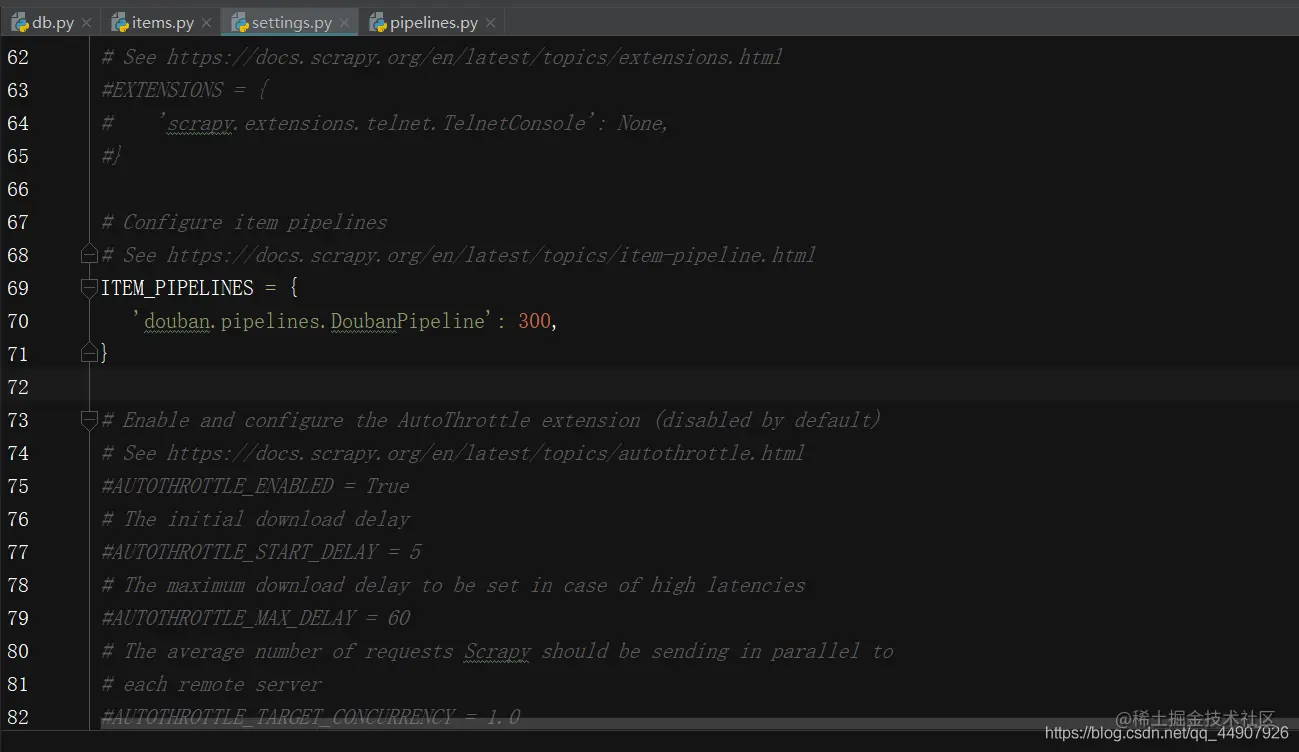
第四步:现在数据已经可以交给管道,那么管道就要对数据进行处理就是操作pipelines.py文件
# -*- coding: utf-8 -*-
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html
import json
class DoubanPipeline(object):
def process_item(self, item, spider):
#为了能写进text json.dumps将dic数据转换为str
json_str=json.dumps(dict(item),ensure_ascii=False)
with open("films.text","w",encoding="utf-8") as f:
f.write(json_str)
return item
复制代码
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
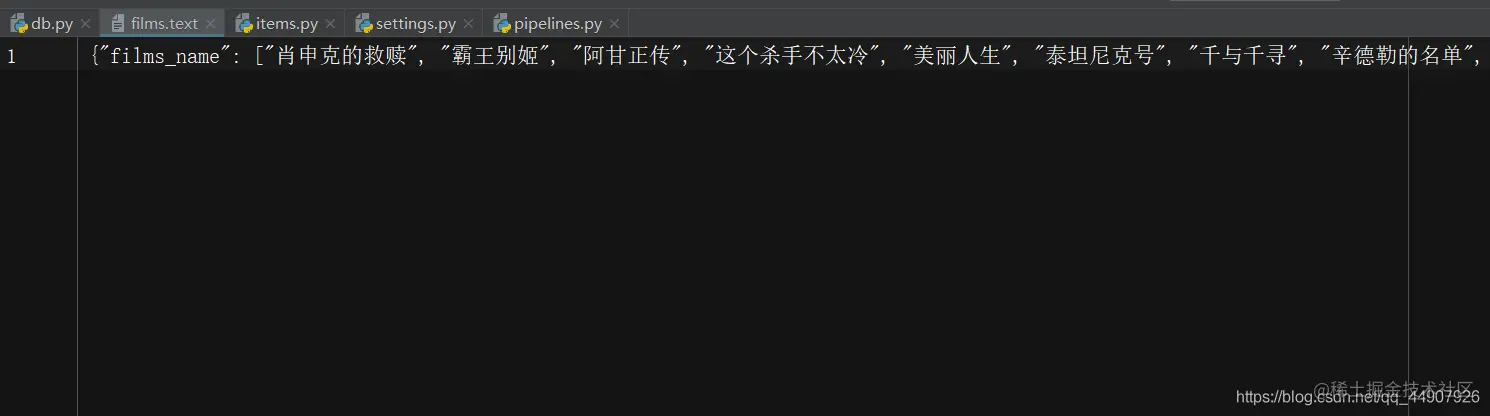
# 实现效果:
# 🔆In The End!
# 👑有关于Me
个人简介:我是一个硬件出身的计算机爱好者,喜欢program,源于热爱,乐于分享技术与所见所闻所感所得。文章涉及Python,C,单片机,HTML/CSS/JavaScript及算法,数据结构等。
从现在做起,坚持下去,一天进步一小点,不久的将来,你会感谢曾经努力的你!
认真仔细看完本文的小伙伴们,可以点赞收藏并评论出你们的读后感。并可关注本博主,在今后的日子里阅读更多技术文哦~
作者:孤寒者 链接:https://juejin.cn/post/7111259081217671205 来源:稀土掘金 著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。